
Introduction
Retrieval-Augmented Generation (RAG) , which combines document retrieval with large language model (LLM), is a potential technique for enhancing the accuracy and relevance of AI-generated responses. This guide will show you how to build a privacy-first RAG system that processes PDFs locally using the following methods:
- DeepSeek-R1 for high-performance text generation.
- LangChain for document processing and retrieval.
- Ollama for running DeepSeek-R1 efficiently on your local machine.
- Streamlit for building an interactive chat interface.
This system is ideal for handling technical, legal, and academic documents, making it a great tool for professionals and researchers.

In this guide, we are using DeepSeek-R1 7B (Para), a powerful open-weight language model optimized for long-context understanding and retrieval-augmented generation (RAG) tasks.
Why DeepSeek-R1 7B (Para)?
- Optimized for paragraph-level retrieval: This model is fine-tuned for handling structured document data, making it ideal for processing technical, legal, and academic PDFs.
- Long-context support: DeepSeek-R1 is capable of processing long documents, ensuring that responses remain coherent and contextually relevant.
- Local inference: Running on Ollama, it eliminates the need for cloud-based LLM APIs, making it fast, private, and cost-effective.
System Architecture for a Retrieval-Augmented Generation (RAG) System with DeepSeek-R1
Below is a high-level system architecture for implementing a RAG-based Chat with PDFs using DeepSeek-R1, LangChain, Ollama, ChromaDB, and Streamlit.
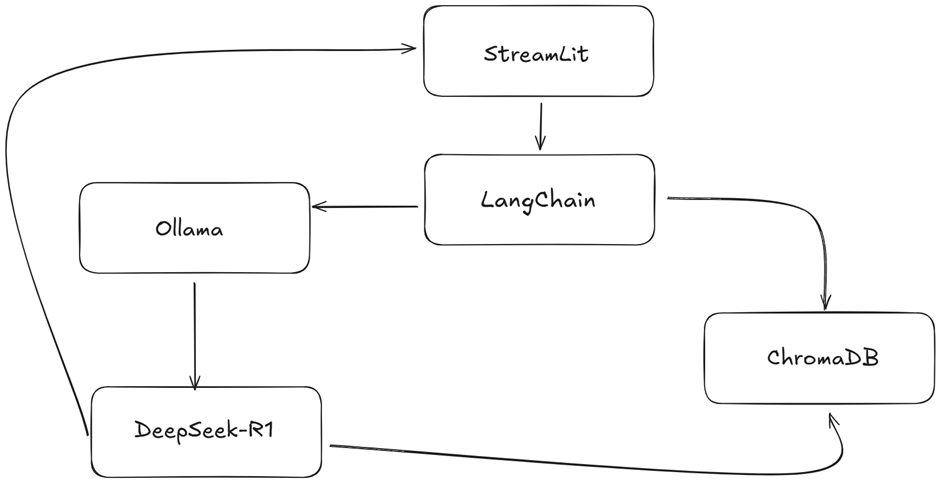
Here’s a breakdown of the key components involved in the architecture:
- Streamlit
- Role: User interface where users can ask inquiries and upload PDFs to engage with the system.
- A user-friendly web interface for uploading documents and entering queries is made with Streamlit.
- A PDF is processed to extract pertinent textual fragments, saved in a database (ChromaDB), and indexed for later retrieval after the user submits it.
- The system will respond to the user’s query by using the pertinent document excerpts that were obtained from the database.
- Text extraction and document processing with PyPDF and LangChain
- Role: In charge of removing text from PDF documents, dividing it into smaller pieces, and archiving them for later use.
- Text can be extracted from PDF files using PDF Loader (PyPDF).
- It scans the PDF file’s whole contents and divides them into manageable parts, such paragraphs or sections.
- The LangChain text splitter is used to create manageable “chunks” or parts of the extracted text for vectorization and retrieval.
- A self-contained unit of information, such as a paragraph or a page, is represented by each chunk.
- Olama Embeddings, or text embedding
- Role: Transform collected text into embeddings, or vector representations, suitable for semantic search.
- Using the text chunks, Ollama Embeddings (DeepSeek-R1) creates vector embeddings that encapsulate each chunk’s semantic significance.
- Semantic search is made possible by the model, which produces numerical vectors that reflect the chunk’s meaning (i.e., discovering relevant information based on meaning, not just keywords).
- The ChromaDB is then used to store these embeddings for quick and easy access.
- ChromaDB: Document Store and Retrieval
- Role : Saves the embeddings (vectorized sections) and enables quick access to pertinent documents in response to the user’s query.
- The vector embeddings of the document chunks are stored in ChromaDB.
- To get the most pertinent chunks, the database can rapidly compare a query’s embedding with those it has stored.
- As a vector database designed for similarity search, ChromaDB finds and ranks documents according to how closely they match the user’s query in terms of semantics using vector embeddings.
- ChromaDB is a vector database optimized for similarity search, which means it uses vector embeddings to find and rank documents based on their semantic similarity to the user’s query.
- DeepSeek-R1 7B Question Answering Model
- Role: Uses the context to construct an answer based on the user’s query and the chunks that were retrieved.
- After processing the acquired context (text chunks), DeepSeek-R1 7B (Para) produces a context-aware response.
- Both retrieval—locating the most pertinent information—and generation—using that knowledge to create a cohesive response—are integrated into the system.
- This approach generates a meaningful and factually accurate natural language response based on the user’s question and the retrieved context.
- The task of analyzing the query and its context, combining the two pieces of information, and producing a clear and concise response falls to DeepSeek-R1.
Step-by-Step Guide to Set Up DeepSeek with Ollama Locally
Step 1: Install Ollama
To use DeepSeek-R1 locally, you’ll need to install Ollama (a local inference platform for LLMs). Ollama is a great tool for running language models like DeepSeek on your machine.
Go to the official Ollama website and download the version for your operating system (Windows/Mac/Linux).
Verify Installation: Once installed, verify that Ollama is correctly installed by running:
ollama --version
Step 2: Download DeepSeek-R1 Model
After setting up Ollama, the next step is to download the DeepSeek-R1 model (7B or Para) via the Ollama CLI.
- Download the DeepSeek-R1 Model: Run the following command in your terminal or command prompt
ollama pull deepseek-r1-7b
For verification:
ollama list all
Step 3: Test DeepSeek-R1 Locally
Run DeepSeek-R1 locally using command:
ollama run deepseek-r1-7b
Optimizing the RAG Pipeline with FAISS, Ollama, and Streamlit.
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by incorporating external knowledge from documents. This blog explains how to build and optimize a RAG pipeline using FAISS for vector search, Ollama for embeddings and LLM, and Streamlit for the user interface. By following these steps, you can create an interactive chatbot that retrieves and processes PDF content.
Step 1: Install Dependencies
Before we begin, ensure all necessary packages are installed:
pip install streamlit pypdf faiss-cpu langchain ollama
These libraries help with PDF extraction, text chunking, FAISS vector search, Ollama LLM, and the Streamlit UI.
Next, import the required modules:
import streamlit as st
import traceback
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings import OllamaEmbeddings
from langchain.chains.question_answering import load_qa_chain
from langchain.prompts import PromptTemplate
from langchain.llms import Ollama
Step 2: Extract Text from PDF
We need a function to read and extract text from uploaded PDFs.
def get_pdf_text(pdf_docs):
"""Extract text from uploaded PDF files."""
text = ""
try:
for pdf in pdf_docs:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text() or ""
cleaned_text = text.replace("\n", " ").strip()
return cleaned_text
except Exception as e:
st.error(f"Error reading PDF: {e}")
traceback.print_exc()
return ""
This function loops through each uploaded PDF and extracts its text while handling errors gracefully.
Step 3: Split Text into Chunks
Since LLMs handle limited token lengths, we split the extracted text into smaller, overlapping chunks.
def get_text_chunks(text):
"""Splits text into chunks using LangChain's RecursiveCharacterTextSplitter."""
try:
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
chunks = splitter.split_text(text)
return chunks
except Exception as e:
st.error(f"Error splitting text: {e}")
traceback.print_exc()
return []
This ensures that queries return better contextual results while preventing information loss at chunk boundaries.
Step 4: Create and Store Vector Embeddings
To enable fast semantic search, we generate vector embeddings and store them using FAISS.
def get_vector_store(chunks):
"""Generates embeddings and stores them in a FAISS vector database."""
try:
embeddings = OllamaEmbeddings(model="deepseek-r1:1.5b")
vector_store = FAISS.from_texts(chunks, embedding=embeddings)
vector_store.save_local("faiss_index")
st.success("FAISS vector store created and saved locally.")
except Exception as e:
st.error(f"Error creating FAISS vector store: {e}")
traceback.print_exc()
FAISS enables efficient retrieval of the most relevant document chunks based on similarity search.
Step 5: Create the Conversational Chain
A retrieval-augmented chatbot needs a prompt template and a model for inference.
def get_conversational_chain():
"""Creates a conversational chain using the DeepSeek model in Ollama."""
try:
prompt_template = """
Context:
{context}
Question: {question}
Provide a concise and accurate response based on the context.
If no relevant answer is found, state that clearly.
"""
model = Ollama(model="deepseek")
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
return load_qa_chain(llm=model, chain_type="stuff", prompt=prompt)
except Exception as e:
st.error(f"Error creating conversational chain: {e}")
traceback.print_exc()
return None
This chain enables retrieval-augmented question answering using context from PDFs.
Step 6: Process User Queries and Fetch Responses
When a user asks a question, we retrieve relevant documents and generate a response.
def user_input(user_question):
"""Processes user query, retrieves relevant documents, and generates a response."""
try:
embeddings = OllamaEmbeddings(model="deepseek-r1:1.5b")
new_db = FAISS.load_local("faiss_index", embeddings, allow_dangerous_deserialization=True)
docs = new_db.similarity_search(user_question, k=8)
except Exception as e:
st.error(f"Error loading FAISS index: {e}")
traceback.print_exc()
return "Sorry, I couldn't find an answer."
if not docs:
return "Sorry, no relevant answer found. Try rephrasing."
try:
chain = get_conversational_chain()
response = chain({"input_documents": docs, "question": user_question}, return_only_outputs=True)
return response.get("output_text", "Sorry, no relevant answer found.")
except Exception as e:
st.error(f"Error generating response: {e}")
traceback.print_exc()
return "Sorry, something went wrong."
This function uses FAISS for similarity search and Ollama for LLM-based responses.
Step 7: Clear Chat History
To improve usability, we add a function to reset chat history.
def clear_chat_history():
"""Resets chat history in Streamlit."""
st.session_state.messages = [{"role": "assistant", "content": "Upload some PDFs and ask me a question!"}]
Step 8: Build the Streamlit UI
Finally, we integrate everything into an interactive UI.
def main():
st.set_page_config(page_title="Gemini PDF Chatbot", page_icon="🤖")
with st.sidebar:
st.title("📂 Upload PDFs")
pdf_docs = st.file_uploader("Upload your PDF files", accept_multiple_files=True)
if st.button("Submit & Process"):
if pdf_docs:
with st.spinner("Processing..."):
raw_text = get_pdf_text(pdf_docs)
text_chunks = get_text_chunks(raw_text)
get_vector_store(text_chunks)
st.success("Processing completed.")
else:
st.warning("Please upload at least one PDF.")
st.title("Chat with Your PDFs 📖🤖")
st.sidebar.button("🗑 Clear Chat", on_click=clear_chat_history)
if "messages" not in st.session_state:
st.session_state.messages = [{"role": "assistant", "content": "Upload PDFs and ask a question!"}]
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
if prompt := st.chat_input("Ask me anything..."):
response = user_input(prompt)
st.session_state.messages.append({"role": "assistant", "content": response})
Now, you can chat with your PDFs seamlessly! 🚀
Conclusion
In this blog, we explored how to build an optimized Retrieval-Augmented Generation (RAG) pipeline using FAISS, Ollama, and Streamlit. By integrating these technologies, we created an efficient PDF-based chatbot that can process documents, generate embeddings, store and retrieve relevant information, and provide conversational responses.
This solution is scalable, lightweight, and cost-effective, making it ideal for applications such as legal document search, academic research assistance, enterprise knowledge retrieval, and customer support automation.